When working with Large Language Models (LLMs), every interaction involves tokens – the fundamental units that determine both the cost and capabilities of your AI integrations. In this tutorial, you'll learn how to track and manage token usage in your Spring AI applications, ensuring you can build cost-effective and efficient AI-powered features.
What are Tokens and Why Do They Matter?
Tokens are the building blocks of text processing in LLMs. They're not exactly words – typically, a token represents about 3/4 of a word in English. For example, the word "springboot" might be split into "spring" and "boot" as separate tokens, while common words like "the" or "and" are usually single tokens.
Understanding token usage is crucial because:
- Tokens determine the cost of API calls to LLM providers
- They affect the context window size (maximum input length)
- Different models have different token limits and pricing structures
For instance, with OpenAI's GPT-4, you might pay:
- $0.01 per 1K tokens for input (prompts)
- $0.03 per 1K tokens for output (completions)
For a better understanding of how tokens are calculated, OpenAI offers a Tokenizer tool that visualizes token breakdown.
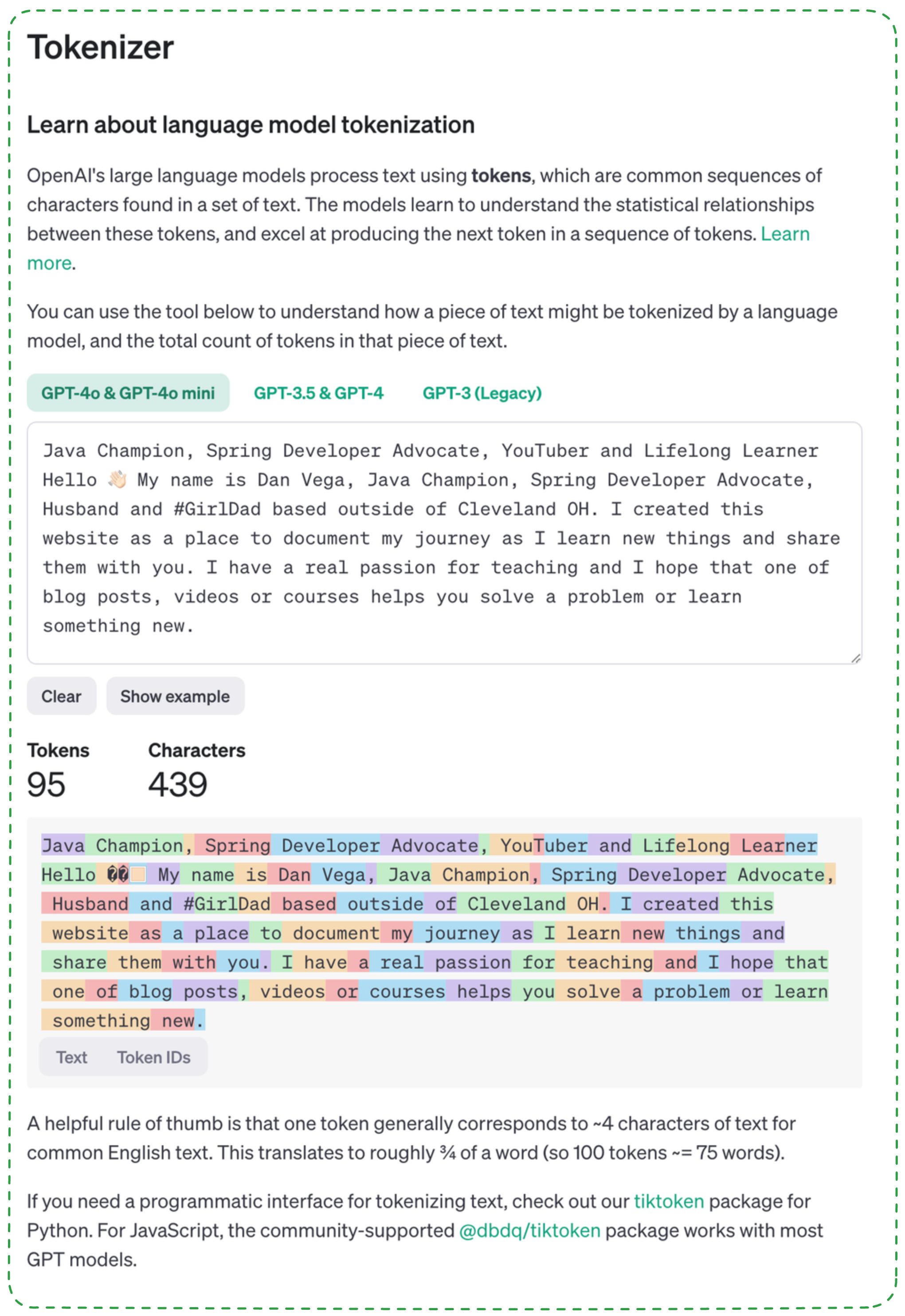
Once you understand what tokens are it's also important to understand that each Large Language Model (LLMs) has a maximum number of tokens that can be sent in or out. Here's an updated table detailing the context window sizes of major LLMs:
| Model | Context Window Size | Description |
|---|---|---|
| GPT-4 (32K) | 32,768 tokens | For handling larger, complex tasks. |
| GPT-3.5 Turbo | 4,096 tokens | Streamlined, fast chat model from OpenAI. |
| Claude 2 | 100,000 tokens | Ideal for long documents and chat memory. |
| Claude 3.5 | 200,000 tokens | Twice the capacity of Claude 2, useful for extended workflows. |
| Gemini 1.5 Flash | 1 million tokens | Designed for in-depth, multimodal analysis. |
| Gemini 1.5 Pro | 2 million tokens | The largest context window, suitable for vast input like entire codebases or hours of media. |
| LLaMA 2 | 4,096 - 8,192 tokens | Open-source model with multiple versions. |
| Falcon LLM | 2,048 - 4,096 tokens | Lightweight, efficient for various applications. |
Note: The context window size refers to the maximum number of tokens (words or characters) the model can process in a single input. Larger context windows allow models to consider more extensive input data, enhancing their ability to generate coherent and contextually relevant responses.
For instance, GPT-4 Turbo has a context window of 8,192 tokens, while Claude 2.1 and Gemini 1.5 offer significantly larger windows of 200,000 and 1,000,000 tokens, respectively.
Setting Up Token Tracking in Spring AI
Let's create a Spring Boot application that demonstrates token tracking. First, create a new project with the required dependencies:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-anthropic</artifactId>
<version>0.8.0</version>
</dependency>
Configure your application properties:
spring.ai.anthropic.api-key=${ANTHROPIC_API_KEY}
spring.ai.anthropic.model=claude-3-sonnet-20240229
Create a basic controller to interact with the LLM:
@RestController
@RequestMapping("/api/tokens")
public class TokenController {
private final ChatClient chatClient;
private static final Logger log = LoggerFactory.getLogger(TokenController.class);
public TokenController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@GetMapping("/basic")
public String getBasicResponse() {
return chatClient.prompt()
.withContent("Tell me a fun fact about Java")
.call()
.getResult()
.getOutput()
.getContent();
}
@GetMapping("/detailed")
public ChatResponse getDetailedResponse() {
return chatClient.prompt()
.withContent("Tell me a fun fact about Java")
.call();
}
}
Creating a Custom Response Type
To make token tracking more intuitive, let's create a custom response type:
public record CustomResponse(String content, Usage usage) {
public record Usage(int promptTokens, int completionTokens, int totalTokens) {}
}
@GetMapping("/custom")
public CustomResponse getCustomResponse() {
ChatResponse response = chatClient.prompt()
.withContent("Tell me a fun fact about Java")
.call();
return new CustomResponse(
response.getResult().getOutput().getContent(),
response.getMetadata().getUsage()
);
}
Automating Token Logging with AOP
Instead of manually logging token usage in each controller method, we can use Spring AOP to automatically track tokens across our application:
@Aspect
@Component
public class TokenLoggingAspect {
private static final Logger log = LoggerFactory.getLogger(TokenLoggingAspect.class);
@Around("execution(* com.example.demo.TokenController.*(..))")
public Object logTokenUsage(ProceedingJoinPoint joinPoint) throws Throwable {
String methodName = joinPoint.getSignature().getName();
log.info("Entering method: {}", methodName);
long startTime = System.currentTimeMillis();
Object result = joinPoint.proceed();
if (result instanceof ChatResponse response) {
Usage usage = response.getMetadata().getUsage();
logUsage(usage);
} else if (result instanceof CustomResponse customResponse) {
logUsage(customResponse.usage());
}
log.info("Method {} executed in {}ms", methodName,
System.currentTimeMillis() - startTime);
return result;
}
private void logUsage(Usage usage) {
log.info("Token Usage - Prompt: {}, Completion: {}, Total: {}",
usage.promptTokens(),
usage.completionTokens(),
usage.totalTokens());
}
}
Don't forget to enable AOP in your application:
@SpringBootApplication
@EnableAspectJAutoProxy
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
Best Practices for Token Management
- Monitor Token Usage: Regularly review token usage to optimize costs and prevent unexpected charges.
- Use Custom Response Types: Create domain-specific response types that include only the information you need.
- Implement Logging: Use AOP or similar patterns to consistently track token usage across your application.
- Set Limits: Consider implementing token limits for different types of requests to prevent runaway costs.
Conclusion
Understanding and tracking token usage is essential when building applications with LLMs. Spring AI makes it straightforward to integrate with various AI providers, and by combining it with Spring's powerful features like AOP, you can create robust token tracking mechanisms.
Remember that tokens directly impact your costs, so implementing proper tracking and monitoring is not just a technical consideration but a business requirement. The approaches shown here will help you build more cost-effective and efficient AI-powered applications.
Have you implemented token tracking in your Spring AI applications? What challenges have you faced? Share your experiences in the comments below!
Related Articles
Spring, Build Me a Coding Agent
Learn how to build an autonomous coding agent in Spring AI using the Spring AI Agent Utils library. This tutorial walks you through creating a CLI-based agent with file system access, shell commands, and skills.
Giving Your Spring AI Agents a Real Browser with the Browserbase Spring Boot Starter
Most AI agents can search the web. But what happens when they need to actually use it? I built a Spring Boot Starter for Browserbase that gives your agents a real, headless browser in three lines of configuration, plus a deep research agent to show it off.
Spring AI Prompt Caching: Stop Wasting Money on Repeated Tokens
If you have an unlimited budget to spend on AI, you probably don't need to read this. If you don't like saving money, feel free to skip this one. But if you're like me and want to reduce your AI application costs, prompt caching is a technique you need to...